Um tweet tem até 140 caracteres. Essa característica sugere que o Twitter possui algo de inofensivo: tirando o teor de cada mensagem, o que as postagens no serviço podem revelar sobre os usuários? Bom, muito mais do que você imagina. Pelo menos é o que indica um algoritmo desenvolvido na Universidade de Rochester que analisa tweets para descobrir se os seus autores estão sob efeito de álcool.
Criar um sistema para esse fim parece coisa de quem não tem o que fazer, certo? Talvez seja mesmo. Mas a ideia mostra como a análise de mensagens do Twitter pode trazer revelações de diversos tipos sobre lugares, acontecimentos recentes, comportamento de grupos e assim por diante. Basta entendermos como o sistema funciona.
Nabil Hossain, líder da pesquisa, explica que o projeto é composto por um algoritmo de aprendizagem de máquina treinado para reconhecer tweets relacionados a álcool, incluindo mensagens que citam palavras em inglês para cerveja, festa, bêbado e assim por diante (no Brasil, creio que “iniciando os trabalhos” estaria entre os termos).
Outra parte desse sistema tenta associar os tweets à localização geográfica dos usuários que os postaram. Não precisa haver exatidão. Quer dizer, quase não precisa: o importante é que essa análise consiga determinar se a pessoa está bebendo dentro de casa ou fora — em um bar, por exemplo.
Para tanto, a equipe de Hossain coletou tweets geolocalizados que foram publicados no primeiro semestre de 2014. Somente mensagens enviadas a partir de Nova York e o Condado de Monroe foram consideradas. Após submeter esse conteúdo a filtros para identificar mensagens com termos relacionados a álcool, os pesquisadores conseguiram reunir um conjunto de 11 mil tweets para os testes.

Esse processo também incluiu a análise de mensagens por participantes do Mechanical Turk, site de crowdsourcing da Amazon. Cada tweet foi analisado por três integrantes do serviço que tiveram que determinar se a mensagem insinua que o autor consumiu álcool e se a postagem foi feita enquanto ele bebia.
Os 11 mil tweets, assim como os parâmetros utilizados para selecioná-los, foram usados para treinar o algoritmo de aprendizagem para que este pudesse realizar esse processo automaticamente. Mas falta a outra parte: determinar se a pessoa que publicou o tweet estava dentro ou fora de casa.
As informações de geolocalização não dão esse detalhe. A turma de Hossain tentou então analisar as pistas: o lugar em que a pessoa postou entre 1:00 e 6:00 da manhã, em que região os tweets daquele indivíduo são publicados com mais frequência, entre outros.
Esses dados ajudaram, mas também não foram suficientes. Hossain recorreu então a uma abordagem complementar: além de termos relacionados a álcool, os tweets tinham que conter palavras que sugerem que a pessoa está em casa, como sofá, televisão, séries e cozinha.

Novamente, essas mensagens foram analisadas por participantes do Mechanical Turk — eles indicaram se o tweet realmente revelava se a pessoa estava em casa — para fins de validação e subsequente treinamento do algoritmo.
Associando esses dados com os parâmetros de geolocalização, o sistema pôde apontar a localização do autor do tweet dentro de uma margem de 100 metros e até 80% de precisão. Sendo mais claro: o algoritmo se tornou capaz de indicar se o autor do tweet estava bebendo, quando e onde.
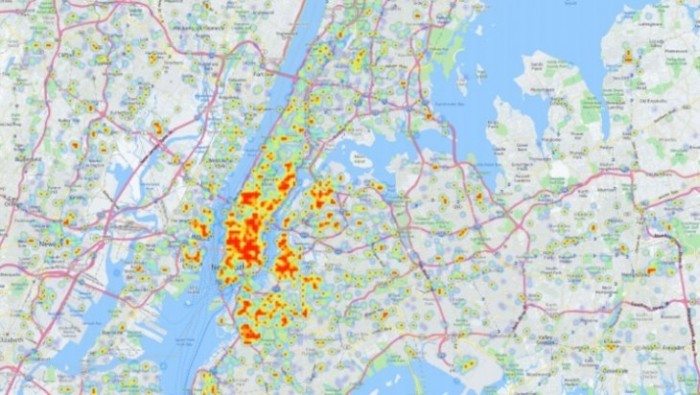
O número de análises que pode ser feito a partir daí é imenso. Os pesquisadores puderam, por exemplo, montar um mapa para identificar os pontos das regiões avaliadas em que há mais consumo de álcool. Eles perceberam que, em Nova York, o consumo de álcool é proporcionalmente maior (talvez porque a cidade tenha muito mais pontos de venda de bebidas). Em compensação, os moradores do Condado de Monroe tendem a beber com mais frequência fora de casa (em distâncias superiores a um quilômetro do lar).
É possível criar vários parâmetros para refinar as análises. Nos testes, a equipe de Hossain configurou o sistema para, por exemplo, mostrar somente as zonas (cada uma delas tendo 10 mil metros quadrados) que registraram cinco tweets ou mais relacionados a álcool. Isso pode indicar uma região que está tendo consumo acima do normal — talvez em virtude de uma festa.
A parte mais interessante desse algoritmo é que ele pode ser usado para coletar e analisar dados sobre vários outros assuntos. Já há ferramentas que analisam tweets para avaliar a audiência de um programa de TV ou a propensão de um candidato ser eleito para um cargo político, por exemplo, mas o novo sistema tem a vantagem de ter adaptação relativamente fácil e ser de baixo custo.
Obviamente, o algoritmo não é perfeito. Resultados mais precisos e confiáveis requerem informações mais detalhadas. A equipe do projeto sabe disso: eles querem incluir na próxima fase parâmetros como idade, sexo e etnia nas análises das mensagens.
Com base nisso, fica fácil encontrar utilidade para o algoritmo: descobrir onde há focos de violência, que regiões passam por surtos de determinadas doenças, quais problemas um local afetado por uma tempestade forte está enfrentando (queda de energia, por exemplo) e por aí vai.
Se há tantas opções de temas, por que a questão do consumo de bebidas alcoólicas foi escolhida para servir de base para o projeto? Hossain dá a entender que essa é uma forma de reforçar a necessidade de debater o assunto, afinal, o álcool está entre as principais causas de morte em várias partes do mundo. Só nos Estados Unidos, estima-se que 75 mil pessoas perdem a vida anualmente por conta da bebedeira excessiva.
Com informações: Inverse, MIT Technology Review




![Como salvar tweets para ler depois [e onde eles estão]](https://files.tecnoblog.net/wp-content/uploads/2019/01/marten-bjork-658221-unsplash-e1548253668279-340x191.jpg)
![Todos os atalhos de teclado do Twitter [Shortcuts]](https://files.tecnoblog.net/wp-content/uploads/2015/12/twitter-hq-100x100.jpeg)
![Como esconder respostas no Twitter [hide replies]](https://files.tecnoblog.net/wp-content/uploads/2019/03/twitter-340x191.jpg)