IA do GitHub que sugere código causa polêmica sobre direitos autorais
GitHub Copilot sugere linhas em código-fonte; debate questiona se sugestões reproduzem códigos já existentes
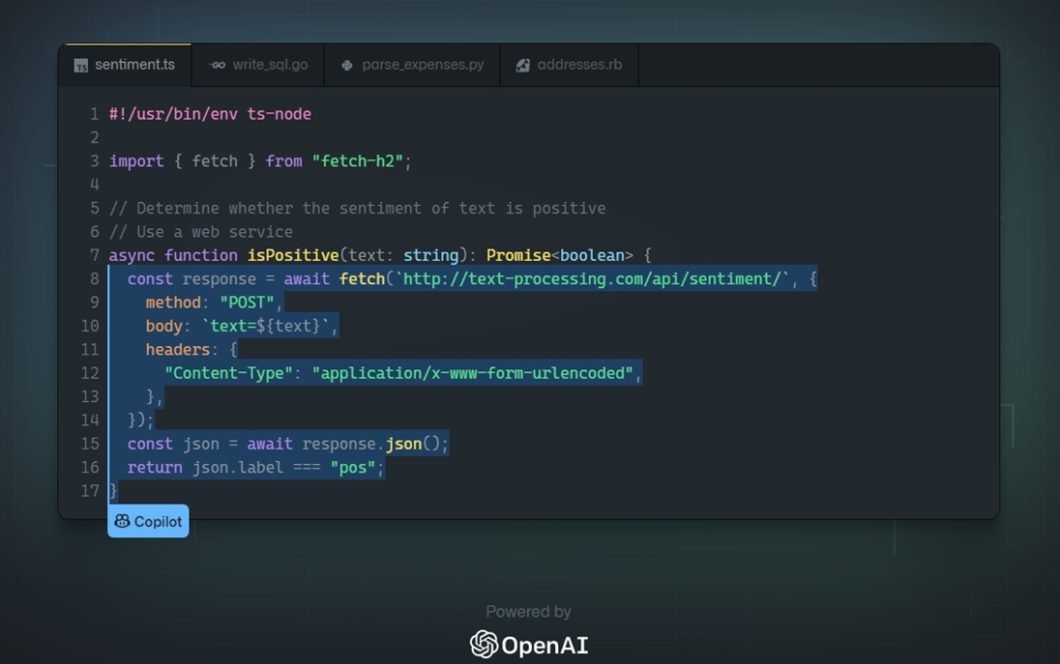
GitHub Copilot sugere linhas em código-fonte; debate questiona se sugestões reproduzem códigos já existentes
No final de junho, o GitHub apresentou o Copilot, ferramenta que sugere linhas de código e até funções inteiras para projetos hospedados na plataforma. O que parecia ser uma excelente ideia logo levantou questionamentos sobre direitos autorais, porém. O motivo? A novidade se baseia em código-fonte público para apresentar sugestões.
O GitHub Copilot é uma ferramenta baseada em inteligência artificial. O projeto é fruto de uma parceria com a OpenAI. O trabalho entre as duas organizações possibilita ao Copilot sugerir, em tempo real, códigos em linguagens como Python, TypeScript, Javascript, Ruby e Go.
Todo projeto de inteligência artificial requer grandes quantidades de dados para ser treinado. Pois bem, o GitHub recorreu a códigos abertos e disponíveis publicamente para treinar o Copilot. Esses códigos estão disponíveis sob licenças como a GPL.
Os problemas começam aí. A GPL exige que trabalhos derivados sejam disponibilizados sob a mesma licença. O que acontece, por exemplo, se o GitHub Copilot reproduzir trechos de códigos disponíveis sob GPL em suas sugestões, mas o projeto como um todo não seguir as condições dessa licença?
De modo geral, a impressão que alguns desenvolvedores tem é a de que o GitHub tira proveito de códigos alheios em benefício próprio, até porque a ferramenta em si não é baseada em uma licença aberta. Mas alguns especialistas em direitos digitais apontam que não é bem assim.
É o caso de Julia Reda, ex-membro do Parlamento Europeu. Em seu blog, ela afirma que a ideia de corporações como a Microsoft (dona do GitHub desde 2018) usar código público parece entrar em conflito com o propósito do copyleft (conceito de licença que concede mais liberdades de uso de uma obra), mas banir essa prática poderia resultar em leis de direitos autorais mais rígidas do que as atuais.
Reda também entende que códigos gerados pelo GitHub Copilot não infringem direitos autorais:
Esse uso só é relevante dentro da lei de direitos autorais se o trecho usado for original e exclusivo o suficiente para alcançar o limite da originalidade.
(…) Os curtos trechos de código que o Copilot reproduz dos dados de treinamento dificilmente atingirão o limite da originalidade.
Julia Reda
Reda também entende que argumentar que o GitHub Copilot gera trabalhos derivados corresponde a supor que uma máquina pode produzir obras, suposição tida por ela como errada e contraproducente.
Nesse sentido, Nat Friedman, CEO do GitHub, declarou no Twitter que treinar sistemas de aprendizado de máquina com dados públicos é um uso justo, ou seja, não submete a prática ao rigor das leis de direitos autorais.
Na mesma rede social, Friedman explicou que o GitHub tem trabalhado para reduzir a reprodução acidental de dados de treinamento e destacou que essa possibilidade existe, mas é extremamente rara.
De fato, a página de FAQ do GitHub Copilot informa que trechos de códigos usados no treinamento são sugeridos apenas em 0,1% das vezes, mas que, de todo modo, um rastreador está sendo desenvolvido “para ajudar a detectar as raras instâncias de código que são repetidas a partir do conjunto de treinamento”.
Mesmo com esse cuidado, o assunto ainda deve gerar discussão, principalmente por abrir espaço para questões ainda pouco debatidas ou polêmicas, por exemplo: até que ponto é razoável o uso de dados públicos para treinamento de inteligência artificial?
Com informações: The Verge.




![Como colocar música com direitos autorais no YouTube [Fair Use]](https://files.tecnoblog.net/wp-content/uploads/2021/04/Como-colocar-musica-com-direitos-autorais-no-YouTube-szabo-viktor-unsplash-340x191.jpg)

