Megavazamento de CPFs tinha algo que “não é normal”: ser organizado demais
Vazamento de 223 milhões de CPFs trazia endereço, telefone, score de crédito, salário e mais dados pessoais; hacker organizou informações de forma incomum
Vazamento de 223 milhões de CPFs trazia endereço, telefone, score de crédito, salário e mais dados pessoais; hacker organizou informações de forma incomum

Faz um ano que o vazamento de 223 milhões de CPFs deixou muitos brasileiros preocupados, querendo saber se seus dados estavam no meio. O volume de informações expostas – incluindo telefone, score de crédito e poder aquisitivo – foi algo sem precedentes no país, e causou certa estranheza porque estava tudo muito organizado… organizado até demais. O hacker pode ter faturado milhões de dólares, mas há indícios de que o objetivo não era só dinheiro.
Em janeiro de 2021, um hacker divulgou o megavazamento de CPFs em um fórum. O anúncio, já removido, trazia um link com uma amostra do que estava à venda – como RG, lista de parentes, endereço completo (com latitude e longitude), salário e status no INSS.
Eram 37 bases no total, organizadas em pastas numeradas e nomeadas de acordo com seu conteúdo, como “03 – Pessoa Fisica – Telefone” e “29 – Pessoa Fisica – Salario”. Cada uma delas trazia dados sobre CPFs diferentes, escolhidos de forma aparentemente aleatória, para dar maior credibilidade.
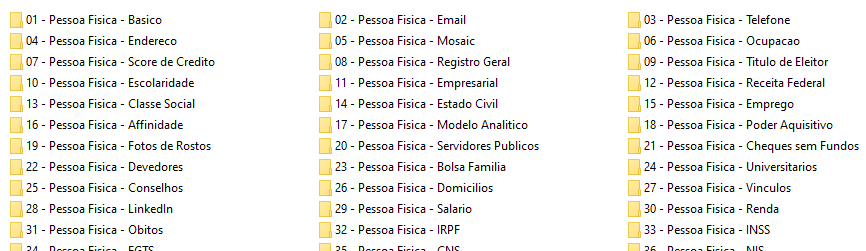
Havia ainda uma tabela separada com 223,74 milhões de CPFs distintos – incluindo de falecidos – que detalhava quais dados estavam disponíveis para cada pessoa. Por exemplo, talvez o arquivo tivesse seu estado civil, mas não seu grau de escolaridade.
“Dos vazamentos que já indexamos no Brasil, nunca tínhamos visto um que fosse tão completo e tão organizado”, afirma Gwin, especialista em análise forense de criptomoedas, em entrevista ao Tecnoblog. Ele trabalha na empresa de cibersegurança Kzarka, que vem acompanhando o megavazamento desde que ele começou a ser vendido na deep web.
No entanto, esse tipo de organização de dados “definitivamente não é normal”, afirma Gwin. Por quê?
Os hackers normalmente prezam por duas qualidades ao vender informações: elas devem estar limpas, e devem estar organizadas – mas não da forma que vimos no megavazamento.
Os dados obtidos através de uma invasão raramente chegam arrumados. “Não vêm seu e-mail e sua senha um do lado do outro”, esclarece Gwin ao Tecnoblog. “Quem faz isso, na verdade, é o hacker, que vai lá e monta esses vazamentos. Ele pega só as informações necessárias, coloca em um arquivo específico, já sabe normalmente de antemão quem é o cliente e o que ele quer.”
Geralmente, os dados são organizados em linhas: por exemplo, para cada CPF, constariam o nome completo, gênero e data de nascimento. Se a base tiver CPF repetido, é um problema, porque as informações são vendidas de acordo com o volume: o comprador se sente roubado e tende a criticar o hacker, que perde moral para futuras vendas, afirma Gwin.
Informações repetidas também geram suspeita: o vendedor pode ser um script kiddie – basicamente, um novato – em vez de um hacker de verdade, “ou talvez ele não saiba limpar o dado, ou talvez esses dados sejam estranhos”, diz Gwin. Segundo ele, existem muitos revendedores de vazamentos, então cada um protege a própria reputação para se manter nos negócios.
No entanto, só dados limpos não bastam: eles precisam estar organizados para serem de fato úteis. “Normalmente, quando você tem um vazamento grande desse, a informação vem organizada de uma maneira que outro hacker consiga rodar algum programa que seja facilmente executável, que seja eficiente – sem rodar por um monte de dados desnecessários – e que seja preciso”, detalha Gwin ao Tecnoblog.
Isto é, os dados precisam estar organizados para serem lidos por um computador, para a máquina encontrar rapidamente a informação. Por exemplo, o formato mais famoso de vazamento é “e-mail: senha”. O especialista diz que esse formato é “matador”: muita gente compra por ser rápido e eficiente. Com um comando simples no Linux, você consegue pesquisar por um e-mail ou senha específica.

Só que o megavazamento de 223 milhões de CPFs não é assim. Em vez de termos uma base simplificada, existem 37 pastas numeradas e nomeadas de acordo com o conteúdo que há nelas: e-mail, classe social, INSS, FGTS etc. O nome de cada pasta tem espaço e letra maiúscula, o que não é muito útil para uma análise de computador.
É porque isso não é feito para máquina; é feito para ser lido por humanos. “O hacker fez um script e pôs tudo bonitinho em cada pasta”, diz Gwin. “Parece que o dado foi fantasiado para ser apresentável, e não simplesmente para existir como dado, que é exatamente o valor dele.”
Isso complica a análise, porque uma pesquisa em 223 milhões de linhas – que já não é exatamente fácil – fica ainda mais demorada. “A máquina vai precisar passar por um monte de ponto-e-vírgula, de espaço, de coisa que não é útil para ela”, salienta Gwin. “É bonito, é útil para a gente entender e para olhar na tela”, mas não para o computador processar.
Então o hacker do megavazamento de CPFs fez um esforço extra para poder chamar a atenção? Gwin acredita nessa hipótese: “o vazamento inteiro, na verdade, foi estabelecido pra ser justamente uma apresentação”.
O especialista lembra que hackers não trabalham só por dinheiro. Sim, o valor dos dados é um grande motivador, talvez o principal; mas há quem faça isso simplesmente por ego. Por exemplo, quem invade páginas da web para substituir o conteúdo – algo chamado de defacement – costuma deixar sua assinatura. “Ele quer prestígio, ele quer palco, ele quer holofote”, diz Gwin ao Tecnoblog.
Se a invasão levar a alguma base de dados, tanto melhor para o hacker: aí a grana vem por oportunismo. “Ao invés de distribuir de graça, ele tenta pelo menos ganhar um pouquinho de dinheiro com isso, mas a motivação não é o dinheiro – é o ego”, explica Gwin. Isso vale especialmente em casos difíceis, seja contra um governo, uma agência de inteligência ou um órgão de segurança. “É legal, é divertido para o hacker se gabar disso”, ele afirma.
Há também quem crie caso com alguma empresa, ficando determinado a manchar sua imagem perante o público. Existe essa possibilidade no caso do megavazamento de CPFs, porque ele foi chamado de “Serasa Experian” ao ser vendido.
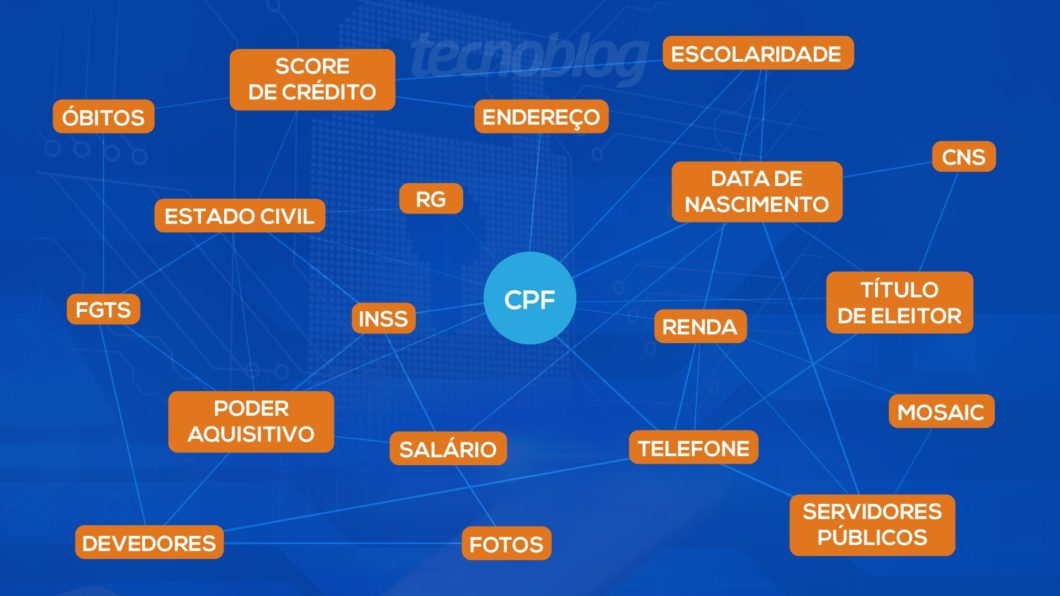
A origem dessas informações pessoais ainda é incerta; na verdade, acredita-se que eles vieram de diversas fontes e foram compilados em um só pacote. Segundo Gwin, o vazamento atribuído à Serasa “tinha justamente os dados mais completos que a gente já tinha visto”.
Ele observa que várias das informações no megavazamento não eram repetidas, ou seja, não estavam circulando antes pela internet. As exceções ficam para o nome, CPF, gênero e data de nascimento; é que, segundo o especialista, isso seria facilmente exposto por qualquer API aberta.
“Muitos dados não precisariam ser da Serasa”, afirma Gwin. “Só que, como tinha muitos dados ali que eram justamente os que a Serasa usa, existe razoabilidade em pensar que eles vieram de um servidor da empresa… Como não encontramos esses dados repetidos em outros lugares – eles só existiam nesse vazamento – a gente imagina, por dedução, que veio da Serasa.”
Em comunicado ao Tecnoblog, a Serasa explica que realizou uma investigação e confirmou não haver evidências de que a empresa sofreu vazamento de dados, nem que seus sistemas tenham sido comprometidos. Os resultados foram corroborados por um instituto de perícias, e o parecer técnico foi entregue às autoridades.
Este é o posicionamento na íntegra:
A Serasa Experian forneceu a todas as autoridades competentes os resultados de sua detalhada investigação sobre as notícias na mídia relativas a dados que foram oferecidos ilegalmente para venda na internet em janeiro de 2021.
Nossa investigação confirmou a nossa conclusão inicial de que não há nenhuma evidência de que a Serasa sofreu o vazamento massivo de dados. Além disso, não há nenhuma evidência de que nossos sistemas tenham sido comprometidos. Esses resultados foram também corroborados por respeitado instituto de perícias após extenso trabalho de análise e revisão, cujo parecer técnico foi entregue às autoridades competentes.
Proteger a segurança dos dados é nossa prioridade número um, e continuaremos apoiando as autoridades nas respectivas investigações.
Uma curiosidade: o especialista se identifica apenas como Gwin porque “o trabalho exige esconder o nome devido a possíveis represálias de criminosos”. Ele explica que usava esse nickname para acessar jogos online e, depois, manteve o apelido para explorar a deep web.
Colaborou: Laura Canal






