O que é processamento paralelo em computação? Saiba benefícios e aplicações
Entenda como funciona a computação paralela, os tipos de processamento paralelo que existem e suas vantagens
Entenda como funciona a computação paralela, os tipos de processamento paralelo que existem e suas vantagens
Processamento paralelo é um método da área da computação que permite que dois ou mais processadores de um computador sejam usados para trabalhar em partes separadas de uma tarefa. Dessa forma, é possível diminuir o tempo gasto na resolução do problema.
O conceito de computação paralela começou a ser desenvolvido no final da década de 1950 por pesquisadores da IBM. Eles acreditavam que um computador único não supriria mais a demanda crescente por poder de processamento. Uma possível solução seria ter dois processadores (ou núcleos) trabalhando simultaneamente.
O primeiro chip comercial com múltiplos núcleos foi o IBM Power4, lançado em 2001. O processador, baseado na arquitetura PowerPC, era um dual-core com frequência de 1,1 a 1,3 GHz. A CPU, que foi a primeira a ter dois núcleos em um único chip de silício, era fabricada em uma litografia de 180 nanômetros.
O paralelismo, que começou sendo usado em aplicações complexas, como computação científica, aprendizagem de máquina e mineração de dados, é atualmente uma técnica comum de processamento em eletrônicos de consumo, como PCs, celulares e smartwatches.
A computação paralela funciona quebrando uma tarefa grande em partes menores que podem ser resolvidas simultaneamente. Para que isso aconteça, o computador deve ter múltiplos núcleos ou threads de processamento, que executam cada tarefa de maneira independente.
Como os núcleos da CPU são independentes, cada um pode executar uma parte da tarefa de forma paralela, diminuindo o tempo de processamento.
A frequência de cada núcleo está relacionada à quantidade de operações que um chip executa por segundo. Em geral, quanto maior o número de núcleos e a frequência, melhor o desempenho.
Nem todas as tarefas se beneficiam da computação paralela. Por exemplo, cada número da sequência de Fibonacci (1, 1, 2, 3, 5, 8, 13…) depende do resultado dos dois termos anteriores, logo, um algoritmo que calcule a série não é naturalmente paralelizável e não tem ganhos de desempenho significativos em um chip multi-core.
Chips gráficos, como GPUs de uma placa de vídeo, lidam principalmente com tarefas paralelizáveis. Eles têm centenas ou milhares de núcleos de processamento que podem aplicar um filtro em cada pixel de uma imagem simultaneamente, o que agiliza o processo de renderização. Por isso, são ideais para games, vídeos e outras aplicações visuais.
GPUs também são usadas para diversas aplicações que se beneficiam da computação paralela por meio de GPGPU (Unidade de Processamento Gráfico de Propósito Geral). Esse conceito se refere ao uso de uma GPU para operações que, tradicionalmente, seriam executadas por uma CPU.
Tecnologias de GPGPU, como o Nvidia CUDA, permitem que um chip gráfico faça centenas ou milhares de cálculos matemáticos de forma simultânea. Com isso, tarefas como mineração de criptomoedas, treinamento de redes neurais e simulações científicas passaram a ser realizadas muito mais rapidamente que com uma CPU.
A taxonomia de Flynn é um sistema de classificação de arquiteturas que se baseia na ideia de quantos fluxos de instruções e quantos fluxos de dados um computador pode manipular simultaneamente. Foi criada pelo cientista da computação Michael J. Flynn em 1966 e é usada até hoje no conceito de computação paralela.
Fluxo de instruções é uma sequência de instruções executadas pelo processador. Uma instrução é uma “ordem” dada ao chip para realizar determinada operação, como uma adição ou subtração. Quando temos várias ordens em seguida, temos um fluxo de instruções.
Já o fluxo de dados é o conjunto de dados sobre os quais as instruções são executadas. Repetindo o exemplo matemático anterior, os números a serem somados ou subtraídos seriam o fluxo de dados em um processador.
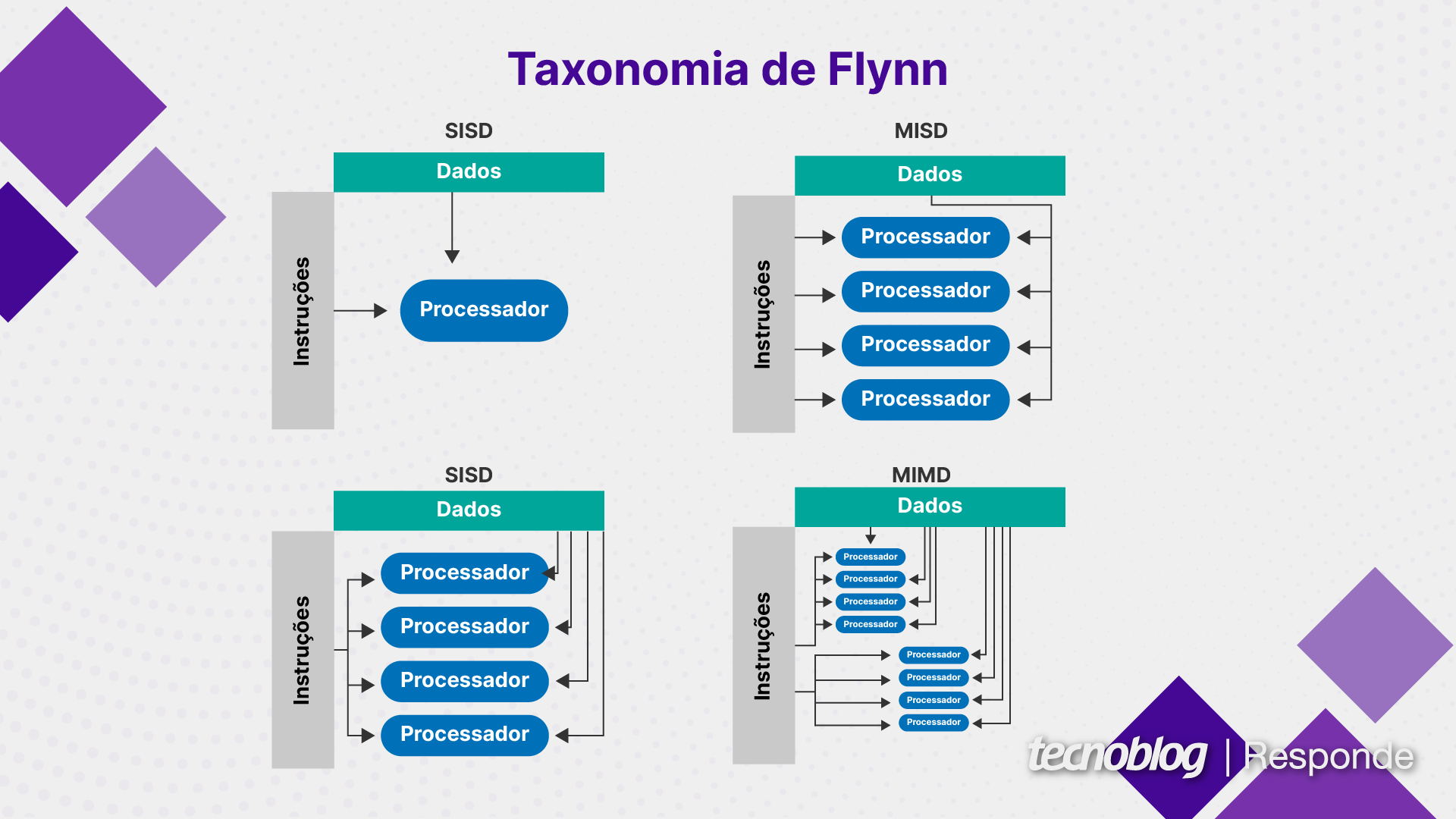
A taxonomia de Flynn divide sistemas em quatro categorias:

O processamento paralelo está presente em diversas aplicações, incluindo os exemplos a seguir:
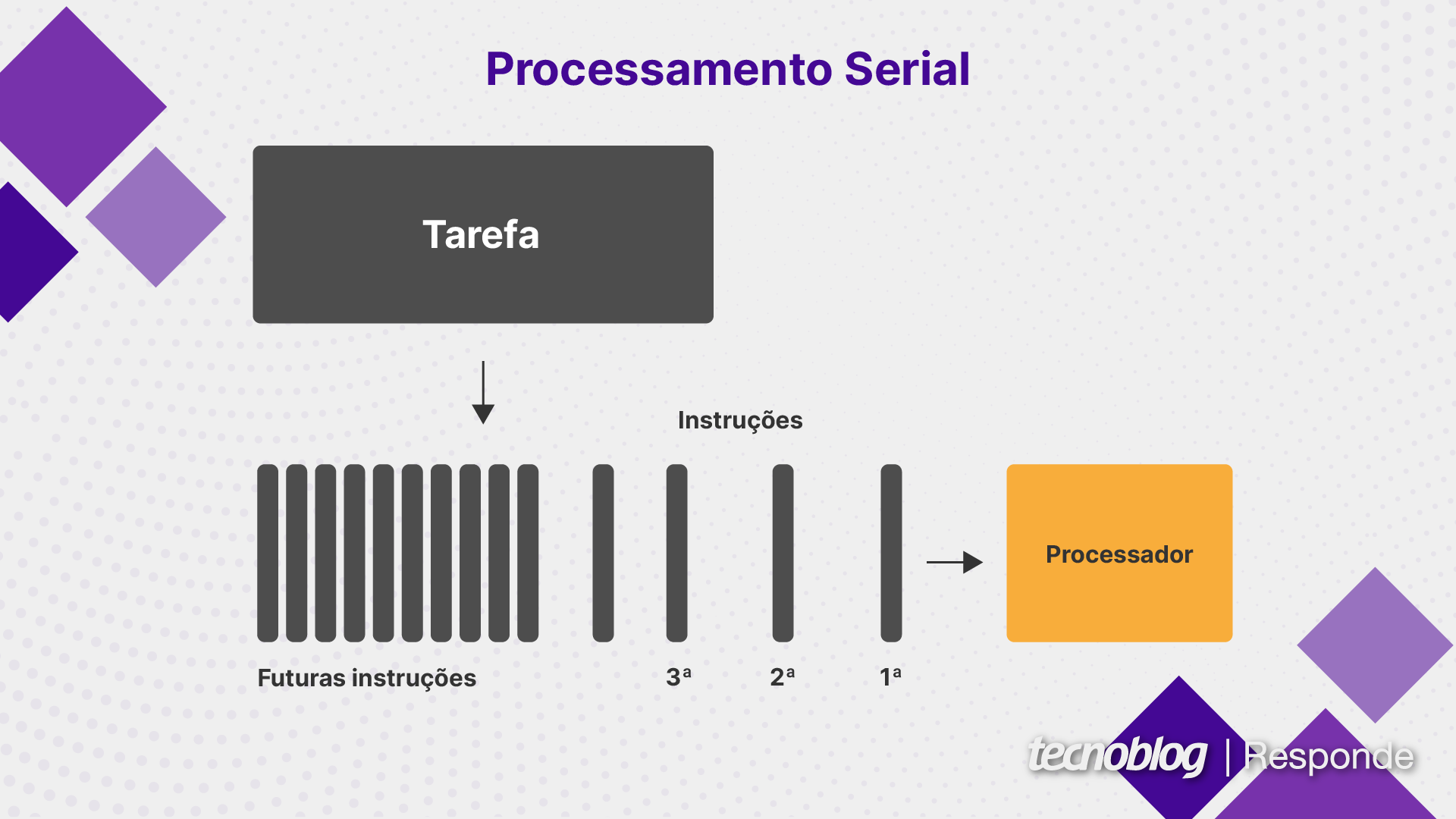
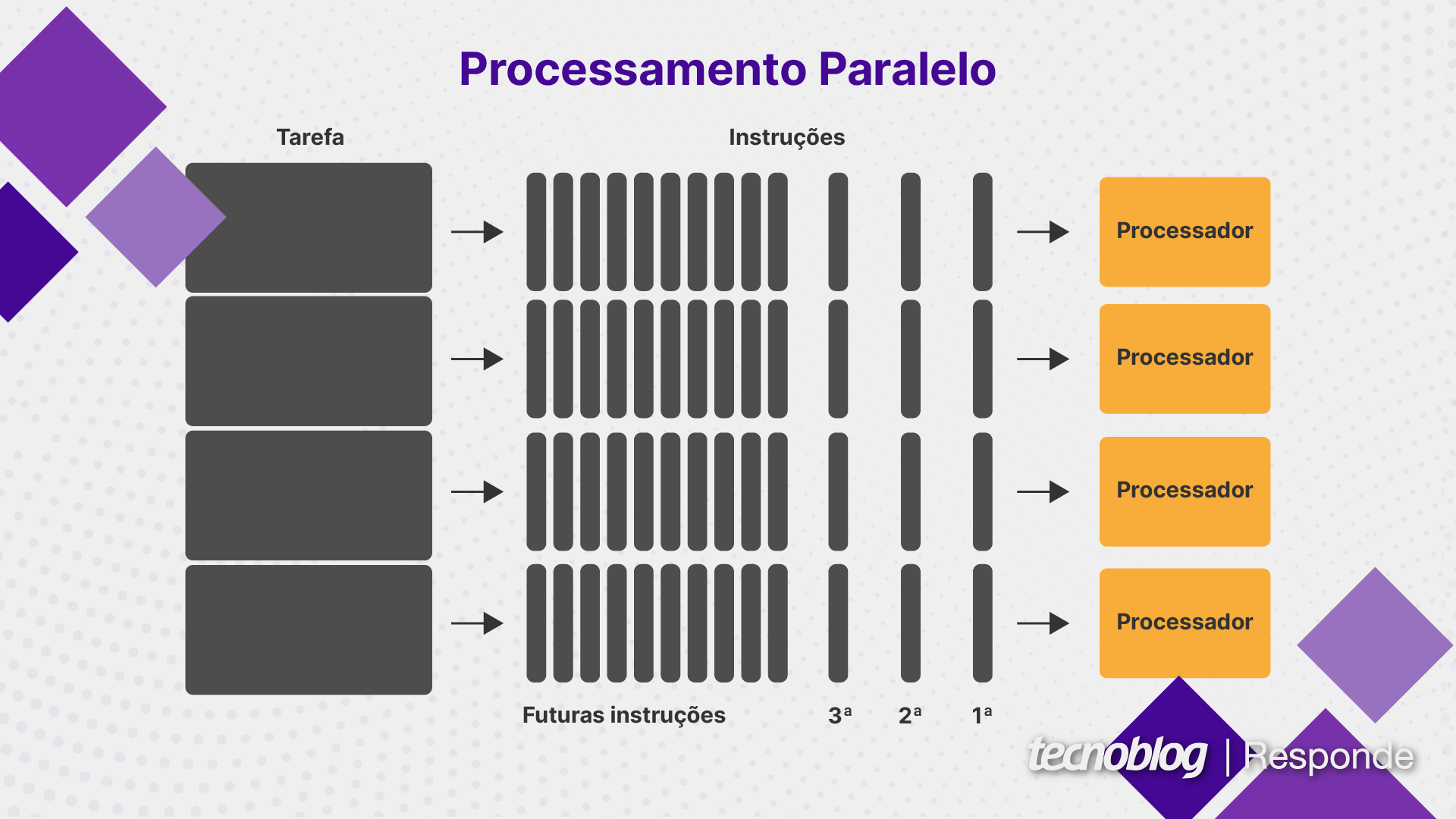
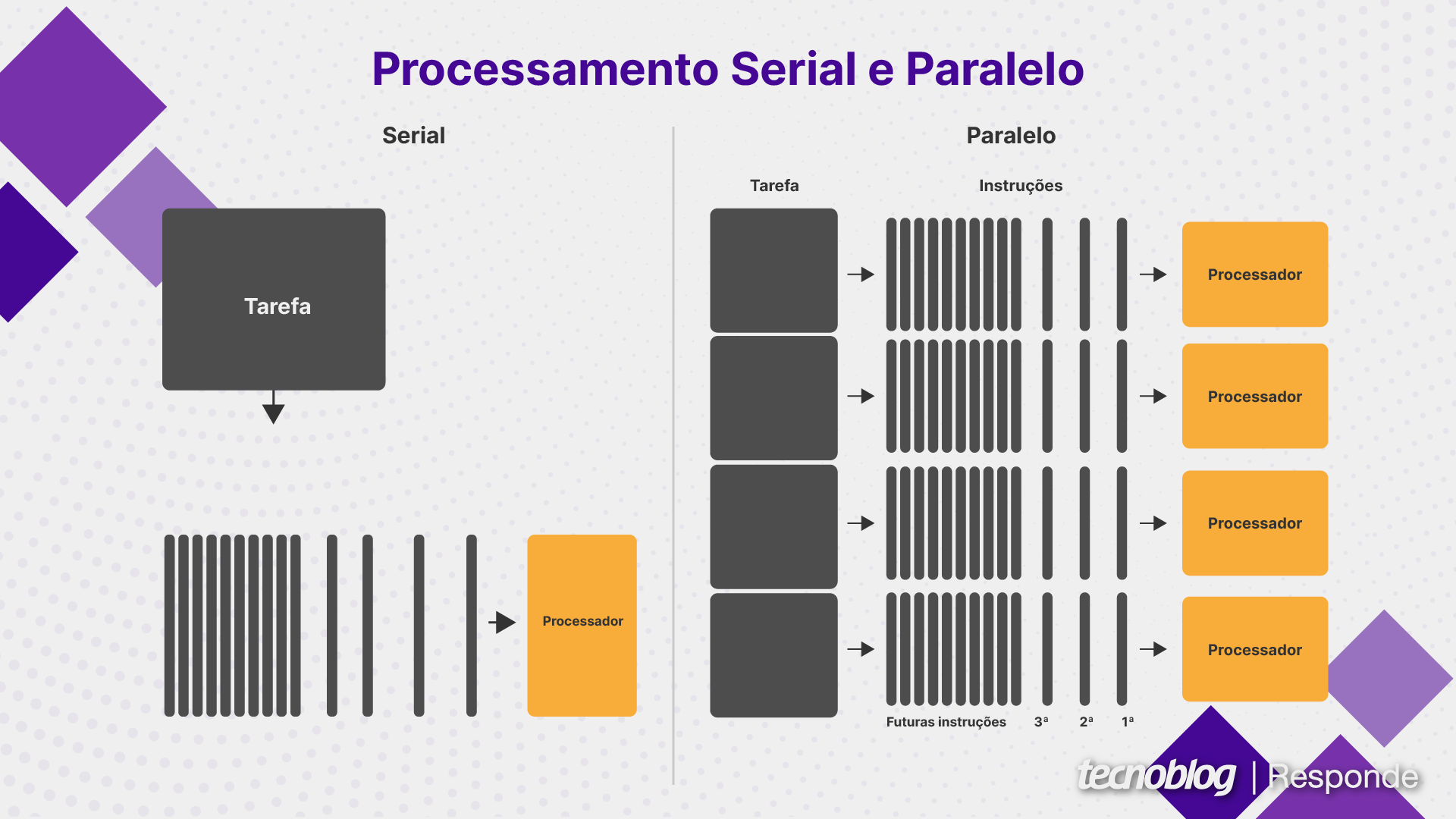
Processamento serial é uma forma de executar várias tarefas em sequência, enquanto o processamento paralelo divide uma tarefa em partes menores que são executadas simultaneamente.
No processamento serial, uma instrução precisa ser concluída antes que a próxima seja iniciada, o que tende a prejudicar o desempenho quando uma tarefa é muito grande. A computação paralela pode ser mais eficiente em tarefas grandes, mas elas devem ser paralelizáveis, ou seja, programadas de forma a aproveitar os benefícios.
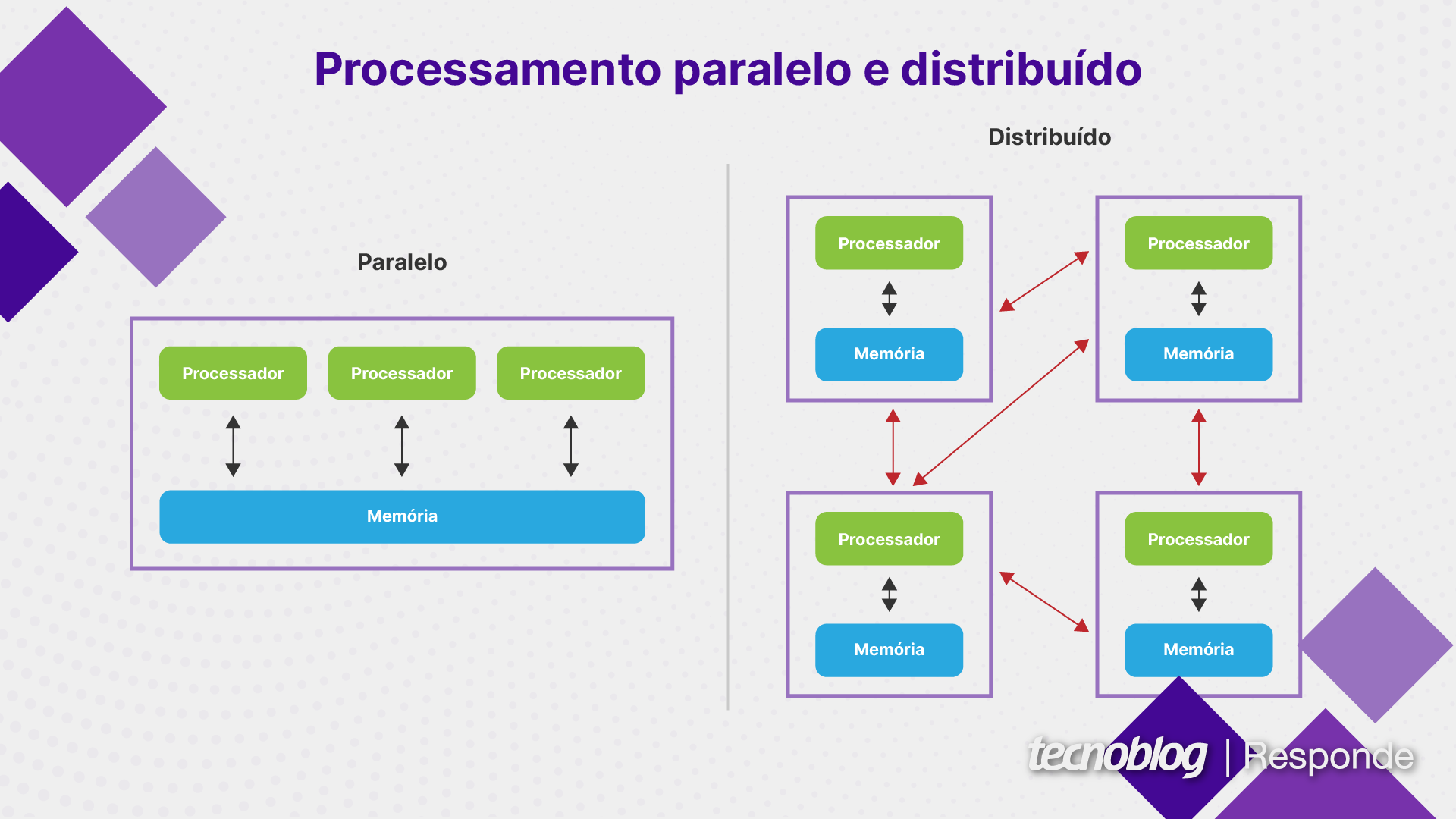
Processamento paralelo é uma forma de executar várias tarefas simultaneamente em um único sistema, enquanto o processamento distribuído divide as tarefas em vários sistemas (chamados de “nós”).
Na computação distribuída, cada nó funciona de maneira independente e pode até mesmo ter seu próprio sistema operacional e memória. Por isso, o processamento distribuído é muito escalável, já que mais nós podem ser adicionados à rede quando forem necessários.
Já a computação paralela geralmente requer uma memória compartilhada que todos os processadores podem acessar. Esse sistema tende a ser menos escalável, porque há um limite físico de quantos núcleos ou processadores podem ser colocados em um mesmo sistema.
Ambos os tipos de processamento oferecem ganhos de desempenho. Porém, a computação distribuída costuma ser utilizadas em tarefas muito grandes, cujo processamento não seria viável em um único sistema.