E se faltar conteúdo humano para treinar a inteligência artificial?
Modelos de linguagem dependem de material humano para evoluir, mas e se a internet ficar repleta de textos gerados pelos próprios LLMs?
Modelos de linguagem dependem de material humano para evoluir, mas e se a internet ficar repleta de textos gerados pelos próprios LLMs?

No dia 18 de julho, pesquisadores da Universidade de Stanford divulgaram um artigo sobre o desempenho do ChatGPT. Numa avaliação de como a ferramenta se saía em certas categorias de prompts, a conclusão foi que o chatbot havia piorado, mesmo após a atualização do modelo GPT 3.5 para o GPT-4.
A descoberta surpreende. Afinal, a lógica é que uma inteligência artificial está sempre aprendendo, e, portanto, se aprimorando. Não há como saber ao certo o que provocou a piora, mas o ponto do estudo é demonstrar a necessidade de permanecer atento ao desenvolvimento dos grandes modelos de linguagem (large language models, ou LLMs). Não dá para supor que estarão sempre evoluindo.
Os achados dos pesquisadores ajudam a ilustrar os possíveis problemas do uso indiscriminado de ferramentas como o ChatGPT. Parece haver um descompasso entre a adoção dos LLMs e o entendimento de como eles funcionam. Mesmo com alucinações e vieses, a IA é muitas vezes é percebida como mágica, o que gera riscos para seus usuários.
Já enfatizamos aqui no Tecnoblog que o ChatGPT mente que nem sente. Não custa lembrar: modelos de linguagem desse tipo trabalham com previsão de palavras, sendo muitíssimo competentes em calcular a probabilidade do próximo item numa frase. Você apresenta uma pergunta, e, com isso, um contexto; a ferramenta prevê as melhores palavras para responder o que você pediu.
Ou seja: o ChatGPT chuta, e é excelente nisso. Mesmo quando acerta, isso se deve a sua capacidade de elencar as palavras mais prováveis num determinado contexto. É para isso que serve todo o material de treinamento do modelo: torná-lo capaz de prever melhor.
É justamente por ser um mecanismo de previsão que há constantes equívocos em suas respostas. Ele não está consultando um banco de dados com todo o conhecimento existente, e sim tentando acertar o próximo termo. Nem sempre consegue. Daí surgem as chamadas alucinações, fatos e fontes totalmente inventados porque seria provável, naquele contexto, dizer algo daquela natureza.
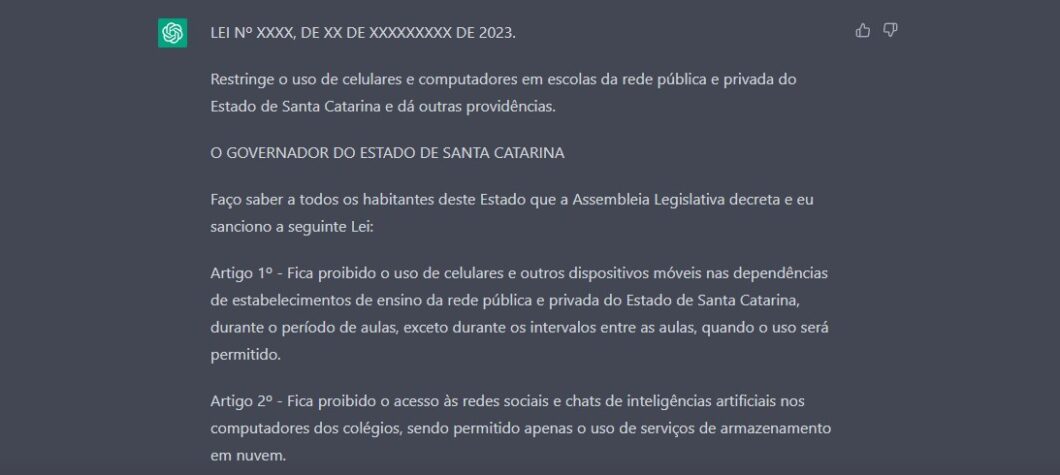
Diante disso, fica claro por que é tão problemático tratar LLMs como gurus. Você já deve ter visto, no Twitter, perfis ensinando a ganhar dinheiro como ChatGPT. Alguns pedem ideias de negócio à ferramenta; outros, dicas de investimento. Outros ensinam como pedir ao ChatGPT criar o seu treino na academia, dispensando o trabalho de um personal trainer.
O problema, obviamente, é que a ferramenta não foi feita para isso, e as chances de você receber uma informação ou “dica” errada são grandes. Pode ser que um dia tenhamos inteligências artificiais capacitadas para esses fins, mas esse dia não é hoje. O ChatGPT nem sabe do que está falando.
Isto não impede, é claro, que experimentos sejam feitos com os textos gerados pela ferramenta. Vários veículos jornalísticos ao redor do mundo já anunciaram o uso de inteligência artificial na criação de notícias, por exemplo, apesar dos riscos.
O caso do site CNET foi bastante comentado no início do ano, com textos gerados por IA contendo erros de cálculo; mais recentemente, o Gizmodo também virou notícia por apresentar conteúdo equivocado num texto que listava os filmes de Star Wars em ordem cronológica (a lista, criada por IA, estava errada).
O uso de LLMs no contexto do jornalismo é motivo de disputas. Por mais que o discurso de muitos executivos aponte para o uso da ferramenta como um auxílio para jornalistas, muitos profissionais da área acreditam que se trata de um convite para uma lógica de produtividade baseada em quantidade, não qualidade.
Falando em quantidade, o número de sites com desinformação gerada inteiramente por IA já está na casa das centenas, de acordo com levantamento da organização Newsguard. O objetivo parece ser gerar textos que obtenham um bom ranqueamento no Google. Resultado: mais cliques, e, portanto, mas renda com anúncios.
Atores mal-intencionados certamente verão em ferramentas como o ChatGPT um atalho para criar mais e mais conteúdo problemático. Mas o ponto é que, mesmo sem uma intenção escusa por parte do usuário, textos gerados por LLMs frequentemente contém erros factuais e informações inventadas.
E, como discutimos no Tecnocast 297, mesmo os profissionais mais atentos deixarão passar algo. É inevitável.
Mas há um fato: criar conteúdo via ChatGPT é muito barato. Assim, é muito provável que vejamos mais e mais conteúdo nascido de ferramentas de LLM, e não de seres humanos, se espalhando pela internet.
Isso poderia gerar dinâmicas curiosas. Afinal, inteligências artificiais são treinadas com material encontrado na internet. Num mundo em que uma parcela significativa dos textos na web foram criados por inteligência artificial, os modelos de linguagem acabariam sendo alimentados por material que eles próprios originaram.
Alguns pesquisadores apontam que este fenômeno causaria o chamado colapso de modelo (model collapse). Ao usar conteúdo autogerados para aprender mais, estes modelos passariam a produzir material menos útil para os usuários. Ou seja: o uso indiscriminado das ferramentas de IA pode prejudicar até mesmo os próprios modelos.
Uma forma de evitar o colapso é garantir que os dados com os quais os modelos são alimentados foram 100% criados por humanos. Isso envolveria pagar por acesso a livros, artigos e notícias, de modo a obter material de alta qualidade e de origem comprovada.

Porém, há um obstáculo: dinheiro. Conteúdo gerado por seres humanos é caro, e as empresas certamente prefeririam economizar. Por isso, já se fala de treinamento com dados sintéticos. É quando uma IA cria material especificamente para treinamento de LLMs. Já há, inclusive, startups vendendo esta tecnologia como serviço, como aponta esta reportagem do Finantial Times.
Como podemos ver, há muita coisa em jogo no desenvolvimento dos modelos de linguagem. Por enquanto, o melhor é prosseguir com cautela. Ou seja: nada de pedir para o ChatGPT fazer a sua série na academia.






