Como ver tweets apagados usando o Internet Archive
Direto do túnel do tempo; saiba como ver tweets apagados usando o Internet Archive e entenda as limitações da ação
Direto do túnel do tempo; saiba como ver tweets apagados usando o Internet Archive e entenda as limitações da ação
Como buscar informações antigas que podem ter sido apagadas da internet ou de perfis utilizando uma ferramenta ao alcance de todos? Veja abaixo, como ver tweets apagados usando o Internet Archive e descubra qual o pulo do gato e as limitações da ferramenta para este fim.
Tempo necessário: 2 minutos
O grande pulo do gato é utilizar a barra de pesquisa por URL do Wayback Machine, disponível na página principal do Internet Archive. Importante lembrar que para ter os registros, o perfil do Twitter precisa ser público e o snapshot da página deve ter sido registrado antes do tweet ser apagado.
O primeiro passo é ingressar na página oficial do Internet Archive. Na região central superior, coloque a URL exata do perfil do Twitter que deseja pesquisar;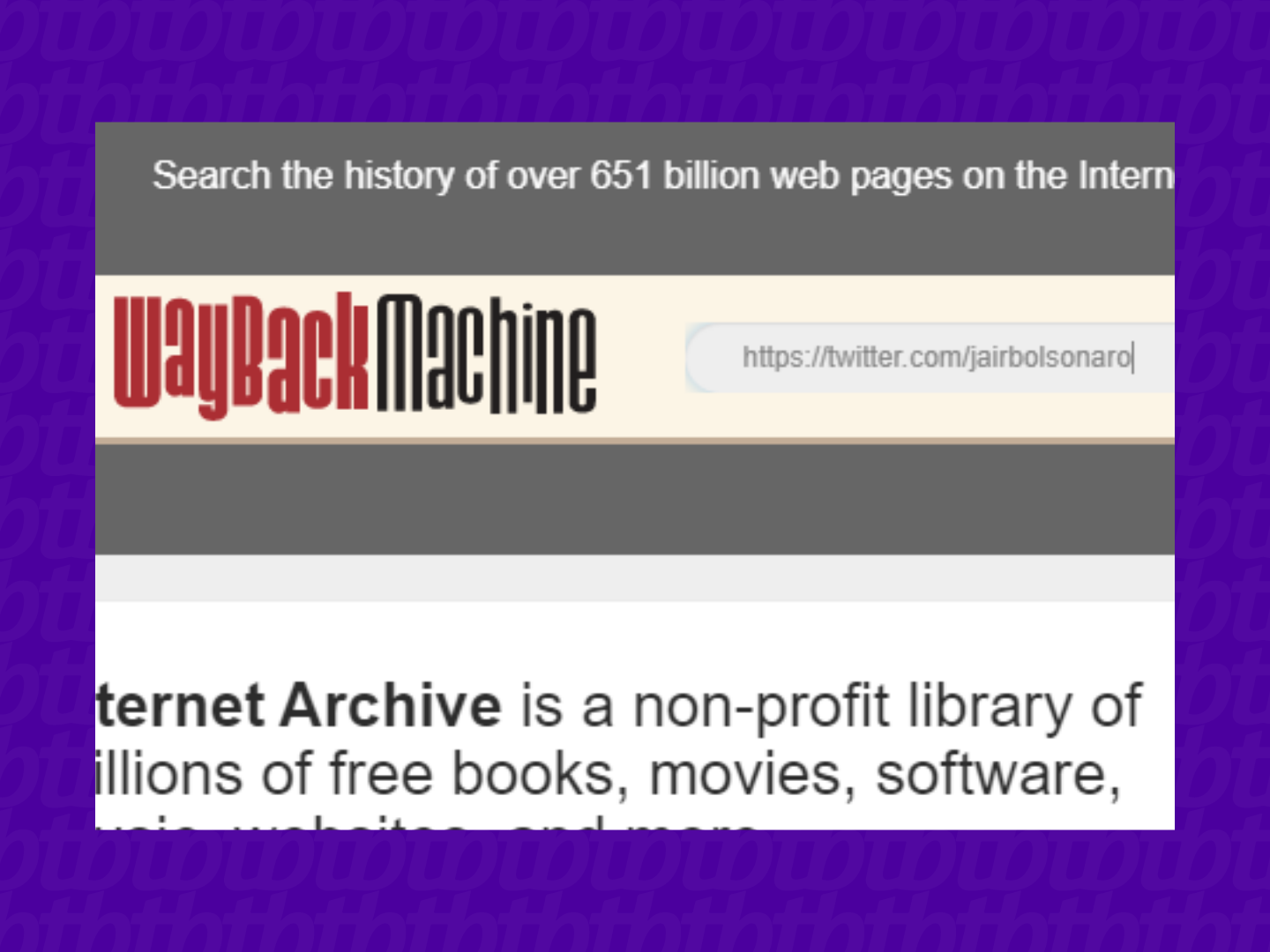
Na tela seguinte, caso existam registros, uma linha do tempo ficará disponível, separada por anos e com o volume de registros. No exemplo, buscamos o registro mais antigo do perfil;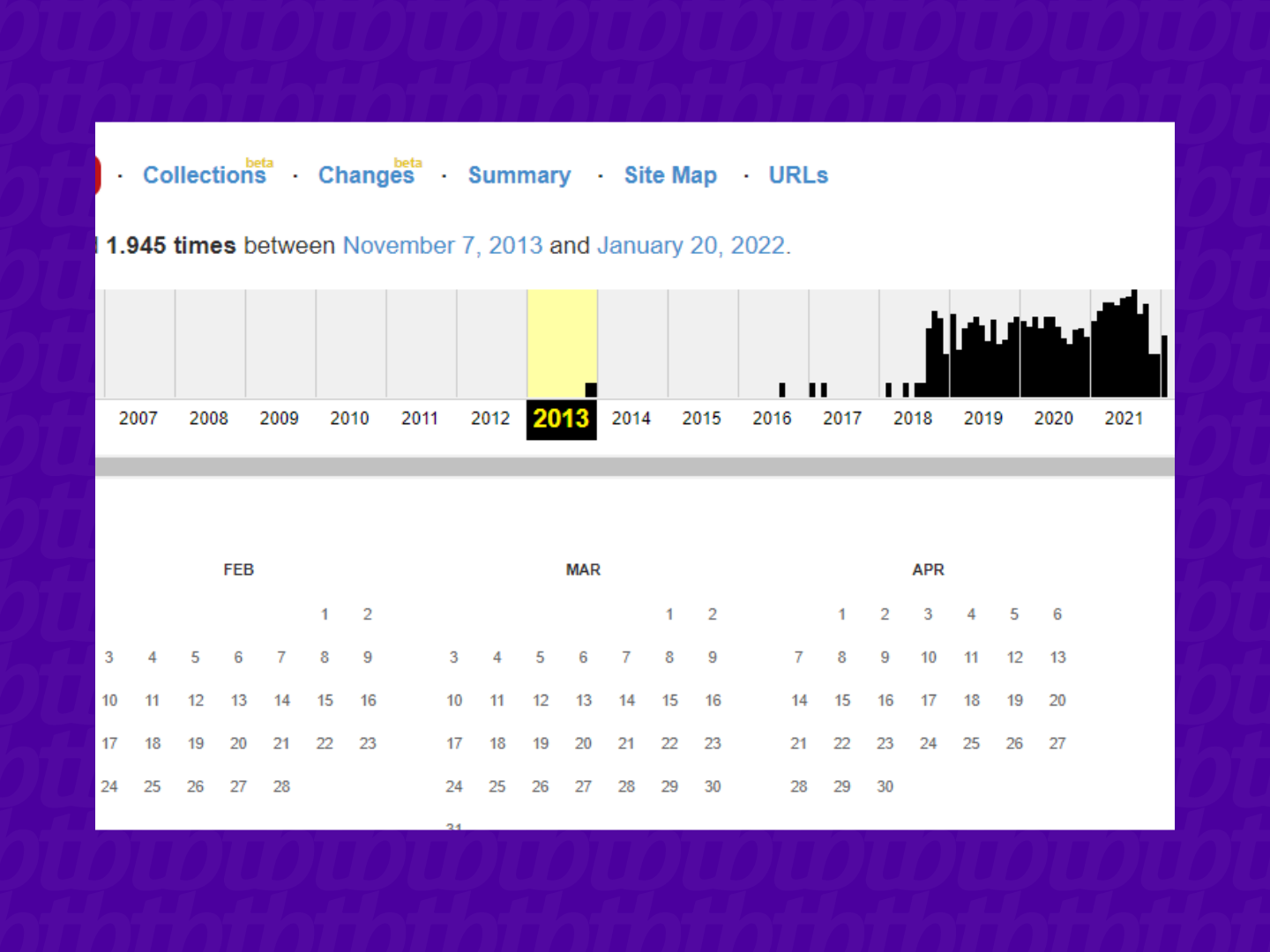
Após definir o ano da pesquisa na parte superior, o calendário abaixo irá mostrar os dias em que foram feitos registros da página. Basta posicionar o mouse sobre a data e, no pequeno menu, clicar sobre o horário do snapshot;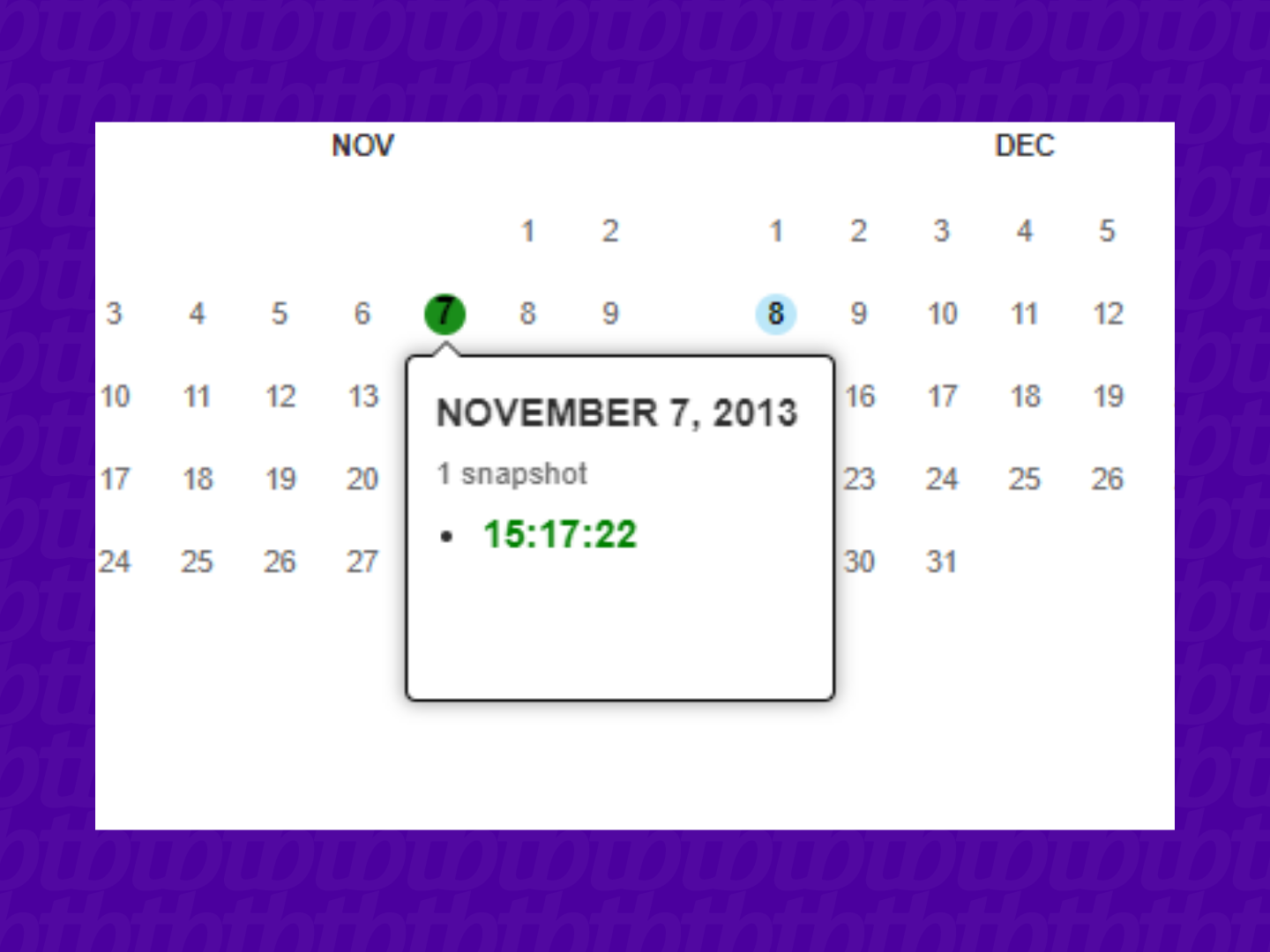
Após clicar, na página seguinte estará disponível a imagem registrada na data. No caso do exemplo, o registro foi feito em 2013, mas o tweet tinha sido postado em 2009.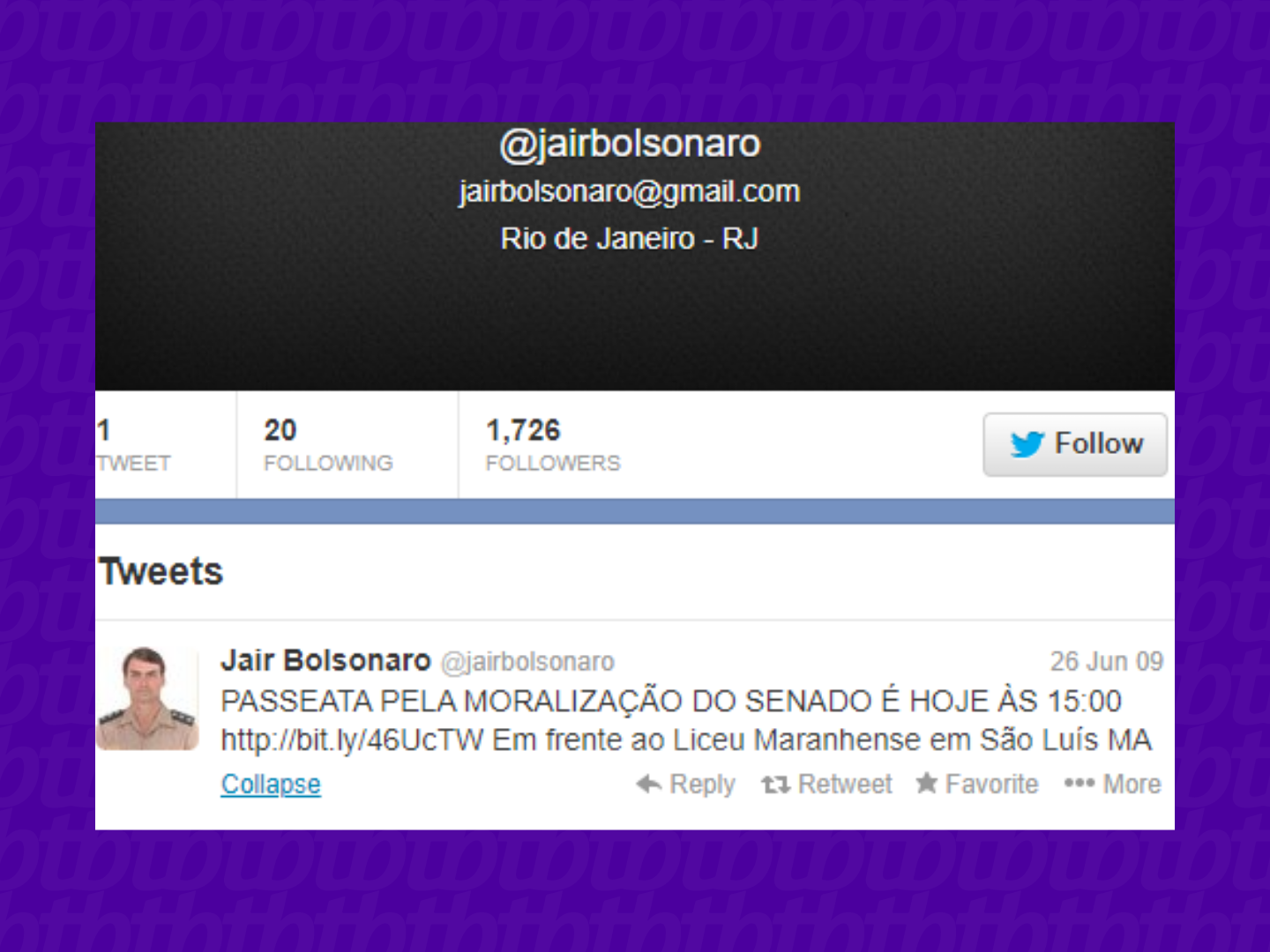
Busquei exemplo nas duas principais pessoas públicas brasileiras, o perfil do atual presidente do Brasil, Jair Bolsonaro e do ex-presidente Luiz Inácio “Lula” da Silva. O perfil de Lula só tinha registros de 2018 para frente, como a ideia era buscar um tweet mais antigo, a melhor opção para exemplo acabou sendo o atual presidente.
O Internet Archive arquiva a web há 20 anos e preservou bilhões de páginas de milhões de sites. Essas páginas geralmente são compostas e vinculadas a muitas imagens, vídeos, folhas de estilo, scripts e outros objetos web. Ao longo dos anos, o Arquivo registrou mais de 510 bilhões desses objetos da web com carimbo de data/hora, que eles chamam de capturas.
O site define uma página da web como uma captura válida, quando o registro é um documento HTML, um documento de texto simples ou um PDF de registro da imagem. É interessante buscar domínios antigos e descobrir como eram as páginas em suas respectivas épocas.
Com informação: Internet Archive 1, 2, 3, 4.

![Como usar a máquina do tempo do Internet Archive [Wayback Machine]](https://files.tecnoblog.net/wp-content/uploads/2022/01/internet-archive-340x191.jpg)