O que é pipeline no processador? Entenda as vantagens da segmentação de instruções
Descubra o que é pipeline, como um processador se beneficia da execução paralela de instruções e por que essa técnica (quase) sempre melhora o desempenho
Descubra o que é pipeline, como um processador se beneficia da execução paralela de instruções e por que essa técnica (quase) sempre melhora o desempenho
Pipeline é um método usado em processadores para executar múltiplas instruções simultaneamente. A técnica melhora o desempenho do sistema e funciona a partir da divisão de uma tarefa em partes menores, que podem ser processadas em conjunto.
O processamento paralelo é uma das principais vantagens do pipeline. Como mais de uma instrução pode ser executada ao mesmo tempo, um chip pode trabalhar de maneira mais eficiente. Entenda o funcionamento do pipeline e suas vantagens na arquitetura de um processador.
O pipeline é uma técnica usada em arquitetura de processadores para melhorar a eficiência e o desempenho do chip. Ele divide o processamento de uma instrução em múltiplos estágios (passos), permitindo que várias instruções sejam executadas ao mesmo tempo.
No contexto de processamento paralelo, o pipeline é um tipo de paralelismo a nível de instrução. Uma instrução é um comando dado a um computador para executar uma tarefa, como operações matemáticas (adição, subtração, multiplicação e divisão), operações lógicas (e, ou) e controle de fluxo (condições, repetições e desvios).
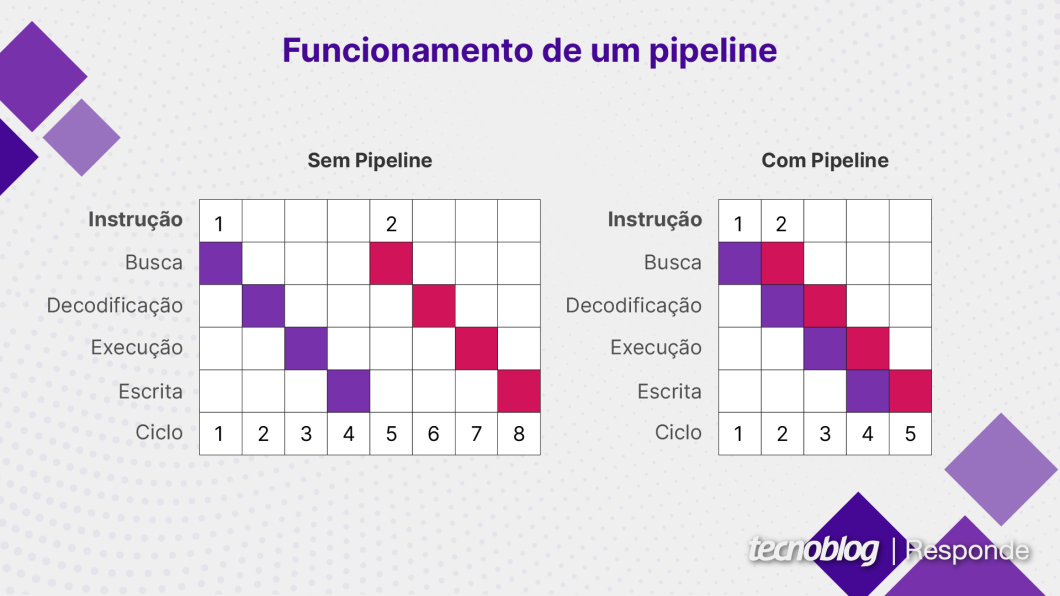
As tarefas que um chip executa são sequências de instruções. A implementação de um pipeline permite que um processador trabalhe na instrução 1 em um estágio, na instrução 2 em outro passo e assim por diante. A quantidade de instruções executadas paralelamente depende do tamanho do pipeline e da eficiência da arquitetura.
Na analogia com um restaurante fast-food, um cozinheiro pode estar preparando ingredientes em uma bancada (instrução 1) enquanto outro monta um sanduíche (instrução 2) e outro coloca um lanche em uma embalagem (instrução 3). Quando esse paralelismo acontece, a comida fica pronta de maneira mais rápida e eficiente.
Um dos benefícios possíveis com um pipeline é a execução de instruções fora de ordem (out-of-order execution, ou OoOE). Quando um chip só pode processar instruções na ordem (in-order execution), uma lentidão em uma instrução causa atraso em todas as instruções subsequentes.
Já em pipeline com processamento fora de ordem, as instruções que não dependem de uma instrução mais lenta podem ser concluídas primeiro. Dessa forma, uma tarefa pode ser executada em menos tempo e usar os recursos do processador de maneira mais eficiente.
Execução de instruções na ordem (in-order execution) é um método no qual as instruções são executadas pelo processador na mesma ordem em que aparecem no código do programa.
Já execução de instruções fora de ordem (out-of-order execution, ou OoOE) é um método no qual o processador decide em qual ordem irá executar as instruções do programa, de modo a diminuir a ociosidade de recursos do chip e concluir a tarefa em menos tempo.

A execução de instruções fora de ordem (OoO) geralmente é mais rápida que a execução na ordem, porque pode executar instruções de forma simultânea, evitando ociosidade e melhorando a eficiência de uso do pipeline do processador.
No entanto, um processador com execução de instruções na ordem pode ser melhor em algumas situações. Se houver muitas instruções que não podem ser paralelizadas, a execução OoO não oferecerá ganhos significativos, por exemplo.
Além disso, uma arquitetura com execução OoO tende a ser mais complexa e consumir mais energia, o que pode limitar o desempenho em computadores com restrições térmicas ou movidos a bateria, como celulares e smartwatches. Nesses casos, um chip com execução na ordem pode ser mais adequado.
Busca, decodificação e execução de instruções são os estágios mais comuns no pipeline de um processador. O ciclo busca-decodifica-executa (fetch-decode-execute) também é chamado de ciclo de instrução. Em muitos pipelines, existem ainda os estágios de acesso à memória e write-back.
No estágio de busca de instrução, o processador localiza a próxima instrução a ser executada. Isso é feito por meio de um registrador, chamado ponteiro de instruções, que guarda o endereço da próxima instrução. Depois da busca, o contador é incrementado e passa a apontar para a próxima instrução da sequência.
No estágio de decodificação de instrução, o processador interpreta a instrução e determina qual operação será executada, como adição, subtração ou carregamento de memória. Ele também define os operandos da instrução, ou seja, os valores ou locais de memória com os quais a instrução irá operar.
No estágio de execução de instrução, a operação determinada na etapa anterior é executada. Um cálculo matemático, por exemplo, é realizado pela Unidade Lógica e Aritmética (ULA) do processador. Já uma operação de memória envolve a movimentação de dados nos registradores do chip. Após a execução, o processador busca a próxima instrução e recomeça o ciclo.
Acesso à memória é o estágio no qual uma instrução carrega (load) ou salva (store) dados em uma memória, que pode ser uma RAM ou uma memória cache (L1, L2 e L3).
Write-back é o estágio no qual o resultado de uma instrução é escrito (write) nos registradores do processador.
O número de etapas varia de acordo com o chip.
Arquiteturas baseadas em RISC têm um estágio clássico de cinco passos: busca, decodificação, execução, acesso à memória e write-back. Porém, a implementação muda dentro da própria arquitetura: uma CPU Arm Cortex-A57 tem pipeline de mais de 15 estágios, enquanto um núcleo Arm Cortex-M0+ possui apenas 2 estágios.
Processadores como os Intel Pentium 4 baseados em microarquitetura Prescott, lançados em 2004, tinham pipeline de 31 estágios, considerado muito longo. Um dos objetivos do pipeline extenso era construir CPUs com clock mais alto, mas os problemas com thermal throttling dificultaram os planos da fabricante.

Não necessariamente. Um pipeline mais longo teoricamente permite que um processador execute mais instruções ao mesmo tempo. Porém, quando há muitos estágios no pipeline, pode haver um aumento no consumo de energia do chip e maior número de riscos (hazards), que ocorrem quando uma instrução não pode ser paralelizada com eficiência.
Hazards (riscos) no pipeline são problemas que impedem a execução paralela de instruções. Quando eles acontecem, uma instrução demora mais tempo para ser processada e o desempenho do chip pode ser reduzido.
Há três tipos de hazards:
Branch prediction é uma técnica usada em processadores modernos que tenta adivinhar o resultado de uma instrução condicional antes que o resultado da instrução seja conhecido. Tem como principal função evitar os hazards de controle no pipeline.
Um hazard de controle pode acontecer quando há uma instrução condicional (se acontecer “isso”, faça “aquilo”) e, para otimizar o uso de recursos, o processador começa a fazer “aquilo” antes de descobrir que “isso” é falso. O objetivo era manter o pipeline ocupado, mas, como as instruções deveriam ser descartadas, houve desperdício de recursos.
Um processador com branch prediction usa o conceito de execução especulativa (speculative execution), ou seja, o chip executa instruções de forma especulativa, já que não tem certeza de que elas realmente deveriam ser executadas. Se a adivinhação estiver correta, o processador ganhou tempo; caso contrário, desperdiçou recursos.

Em geral, os mecanismos de branch prediction e execução especulativa são bastante precisos em processadores modernos com pipeline de execução fora de ordem, logo, o ganho de desempenho compensa os desperdícios. No entanto, essa tecnologia pode ter vulnerabilidades, como a Spectre, descoberta em 2018, que afetava quase todos os processadores do mundo.






