É assim que o Google entende a linguagem que você fala
Batizada de SyntaxNet, a tecnologia de inteligência artificial tem 94% de eficiência no inglês
Batizada de SyntaxNet, a tecnologia de inteligência artificial tem 94% de eficiência no inglês

Um dos maiores desafios da inteligência artificial é entender como funciona a linguagem humana — e também é um dos pontos mais importantes, talvez o principal, da IA. Se os robôs interagirem diretamente conosco, como em ferramentas de atendimento, eles precisam entender como nos comunicamos.
Mas essa tarefa é bem difícil por si só: não são apenas palavras ou caracteres soltos envolvidos, mas também contexto, conhecimento de mundo e uma boa interpretação para saber como lidar com ambiguidades e o que o texto quer dizer. Levamos décadas para conseguir formar tudo isso — mas essa ferramenta do Google não precisou de tanto tempo assim.
Batizado de SyntaxNet (e não SkyNet, apesar de parecer bastante), a ferramenta faz parte do TensorFlow, biblioteca de aprendizagem de máquina do Google. Ela pode ser treinada para trabalhar com qualquer idioma, uma vez que primariamente é ensinada a sintaxe da língua para a ferramenta.
Ou seja, a partir de redes neurais e várias tentativas, ele aprende a classificar cada palavra do idioma e entendê-lo no conjunto da frase como deveria. Elas são classificadas por categorias gramaticais, como verbos, substantivos, pronomes, advérbios, adjetivos, conjunções, etc.
São 12 classificações universais, mas existem também subcategorias: os substantivos, por exemplo, podem ser classificados como substantivo singular ou plural.

Depois, a ferramenta, de certa forma, interpreta o que cada palavra significa na frase, construindo arcos entre as palavras e visualizando sua relação sintática. É mais ou menos como a nossa leitura acontece, só que para nós é meio que automático — você precisou pensar muito para entender o texto até aqui? Aposto que um computador precisaria de bastante processamento para catalogar todas essas informações.
O interessante é que todo esse sistema pode ser adaptado para outras línguas e modificada de acordo com as necessidades de cada idioma. O chinês, por exemplo, tem 294 classificações (!) de categorias gramaticais. Depois de um tempo, o sistema pode ser treinado para entender as especificidades de cada idioma. SyntaxNet seria esse sistema geral, mas o Google já treinou uma ferramenta para entender o inglês, e a nomeou de Parsey McParseface.
Frases pequenas, como demonstra o Google, são relativamente fáceis de serem lidas. O exemplo de Alice viu Bob é tranquilo de ser processado porque só tem dois substantivos e um verbo. O verbo “ver” é a raiz da frase, que se relaciona com Alice (foi ela quem viu o Bob) e com Bob (que foi visto por Alice). Até aqui, tudo ok.
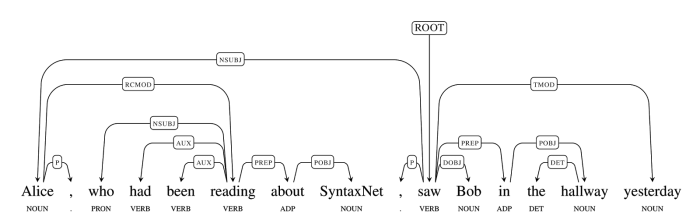
Uma frase mais incrementada do exemplo acima também não enfrenta muitas dificuldades, ainda que apresente dois acontecimentos diferentes e um aposto. A tradução é: Alice, que estava lendo sobre o SyntaxNet, viu Bob no corredor ontem. Dá para identificar facilmente o sujeito (Alice) e o objeto (Bob) do verbo ver, quem estava lendo (Alice) e verificar a flexão do ver pela expressão temporal ontem.
Com o entendimento correto da frase, daria até para o sistema responder perguntas sobre o sistema, como “quem Alice viu?”, “quem viu Bob?”, “sobre o que Alice estava lendo?”, ou até “quando Alice viu Bob?”.
Os resultados são impressionantes: o Google diz que a precisão desse sistema é de 94% em textos bem escritos, enquanto na web o desempenho cai para 90%. Segundo eles, os humanos podem checar a uma precisão de até 97%, então já é um número bem próximo. Mas não comemore tão cedo.
Vários empecilhos impedem que a ferramenta tenha um desenvolvimento tão fácil. O principal é a ambiguidade, que pode não estar visível para muita gente, mas o SyntaxNet (ainda) não tem o mesmo conhecimento de mundo que nós. Dessa forma, um texto de até 30 palavras pode ter de centenas a milhares estruturas sintáticas possíveis, que o computador deve analisar e encontrar a certa.
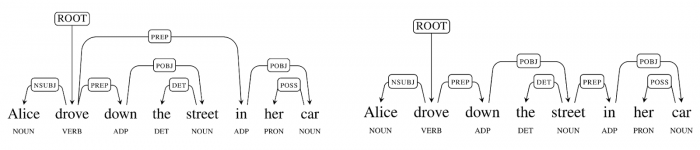
Uma delas, de apenas 8 palavras no original, é demonstrada pelo próprio Google. Alice desceu a rua em seu carro. Para nós é claro que Alice simplesmente desceu a rua em seu carro, mas outra interpretação que pode ser feita é que “carro” é uma espécie de local. Ou seja, a rua estaria dentro do carro (!). Para entender melhor essa confusão, troque carro por bairro. Alice desceu a rua em seu bairro. É mais ou menos como um computador poderia interpretar a frase.
Trata-se de uma interpretação bem fora do comum para nós, mas um computador precisaria de conhecimento de mundo para entender a frase corretamente. Segundo o buscador, é um enorme desafio para os computadores lidarem com a ambiguidade como a gente. “Muitas ambiguidades como essa em frases maiores podem criar uma explosão de fatores combinatórios no número de estruturas possíveis por frase. Normalmente a maioria dessas estruturas é muito improvável, mas é possível e o computador precisa aprender qual destacar”, diz o post no blog.
Com tantas decisões que a IA precisa lidar, o SyntaxNet recorre a redes neurais e a relação entre todas as palavras analisada várias vezes. Eles usam um modelo de busca que, em vez de pegar a melhor decisão logo de cara, considera várias hipóteses em cada passo do processamento e vai descartando-as ao longo do processo de consideração.
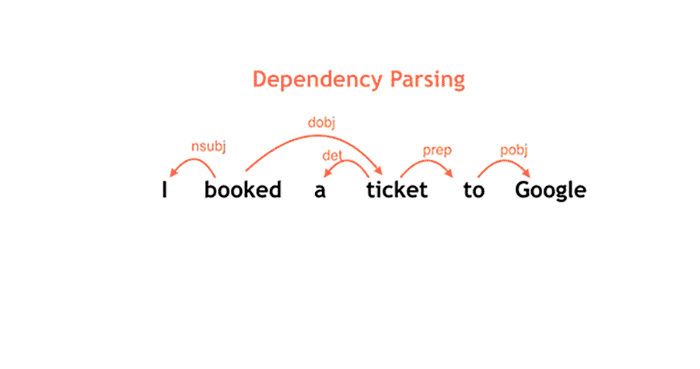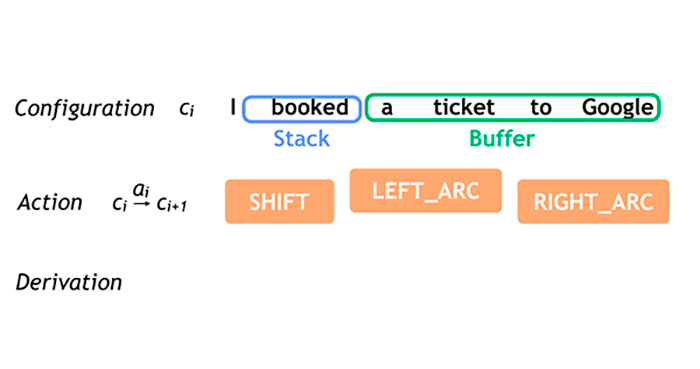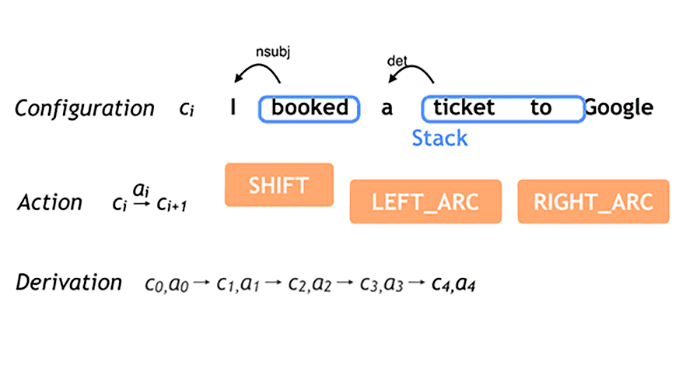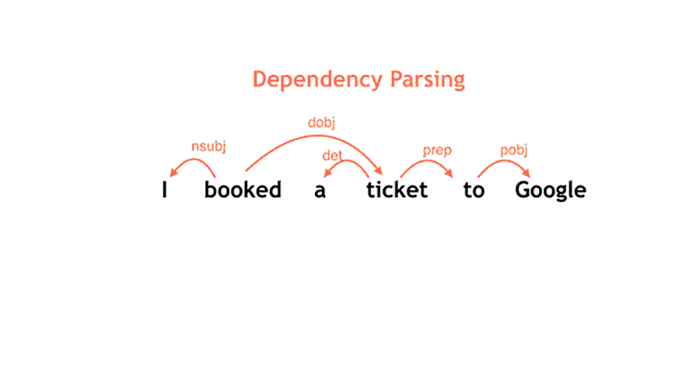
No gif acima, você pode ver mais ou menos como funciona o processamento de frases do SyntaxNet. O buffer, em verde, mostra as palavras que ainda não foram processadas; o stack é uma espécie de pilha de palavras que estão para serem processadas. Os marcadores em laranja são responsáveis pelo processamento das palavras.
Observe que, conforme as palavras vão sendo lidas e classificadas, os arcos vão sendo criados para determinar o sentido da frase. Imagina-se que tudo isso é feito em questão de segundos, várias e várias vezes para criar várias hipóteses que constroem o entendimento da frase.
Desde o começo, a inteligência artificial tenta entender a linguagem humana. Mas, como demonstramos acima, a incerteza é muito grande, apesar do desenvolvimento nesta área hoje ser relativamente bom. É necessária a criação de um contexto para absorver a informação, o que os humanos aprenderam a vida toda a fazer, mas nas máquinas isso deve ser criado do zero.
É um processo difícil, mas estritamente necessário para ferramentas de chat como o Bot Framework da Microsoft. Por lá, a ideia é ir perguntando a um atendente humano o que o consumidor quer e, conforme o robô vai errando, sua interpretação vai aprimorando. Também há uma certa tentativa e erro envolvida, mas é mais frequente.
No caso do SyntaxNet, ele é treinado para entender a língua propriamente dita, mais ou menos na visão de um linguista, e aprende a entender qual é a frase mais provável de ter um significado aceito. O Google diz que esse é um dos sistemas mais complexos que eles já treinaram com o TensorFlow — é de se imaginar, principalmente considerando o número de hipóteses para entender um texto que ele pode criar para interpretar o que esse conjunto de palavras quer dizer.
Como explicamos no especial que detalha a história da inteligência artificial, a estimativa é que só daqui a 20 anos um computador consiga enganar o homem. O principal teste que mede isso é o de Turing, no qual um humano tem que completar uma conversa com uma máquina e ela tem que falar e agir como uma pessoa normal, para que engane o sujeito.
É mais ou menos o que o Google faz no Smart Reply do seu cliente de e-mail Inbox, que usa a inteligência artificial e o processamento de linguagem para gerar “respostas prontas” a e-mails. Ainda é um projeto muito cru, mas quem sabe ele não consegue interpretar o que o e-mail diz e pensar em respostas mais elaboradas? Assim você não precisaria nem usar o e-mail fora do horário de trabalho.
Com os avanços nesta área, pode ser que os robôs comecem a se passar por atendentes via chat bem mais cedo que pensávamos. O Google reconhece que ainda há avanços a serem feitos, como o conhecimento de mundo e o raciocínio contextual, que devem ser embutidos em ferramentas como essa. Será que em alguns anos já conversaremos naturalmente com robôs?