Ferramenta da Meta recria voz da pessoa em questão de segundos
Voicebox requer que usuário insira uma breve gravação de si próprio. Na sequência, sistema é capaz de produzir novas falas a partir de texto escrito.
Voicebox requer que usuário insira uma breve gravação de si próprio. Na sequência, sistema é capaz de produzir novas falas a partir de texto escrito.

A Meta anunciou o desenvolvimento de uma ferramenta de inteligência artificial capaz de gerar falas humanas. O modelo precisa ser abastecido com algumas frases gravadas pelo usuário. Depois, o Voicebox permite criar novos áudios a partir de texto escrito. O próprio Mark Zuckerberg surgiu, num clipe divulgado via Instagram, falando bom português – com direito a um “s” bastante carioca na palavra “ todos”. Tudo gerado por IA.
De acordo com o conglomerado digital, bastam apenas 2 segundos de amostra de áudio para que o sistema consiga produzir novas falas. A ideia é realizar o text-to-speech para evitar os transtornos de eventualmente regravar todo o material de áudio.
Ainda segundo a empresa, a tecnologia permitiria que pessoas com deficiência visual ouçam as mensagens dos amigos ou que personagens não-jogáveis de games – os famosos NPCs – tenham voz. O Voicebox também poderia fornecer sons naturais para assistentes de voz.
Confira em ação no vídeo abaixo:
Outro ponto importante diz respeito à edição de conteúdo. No exemplo, Zuckerberg está gravado um áudio quando se escuta uma buzina. A ferramenta, porém, consegue “limpar” o material. Hoje em dia existem softwares profissionais e outros amadores com função similar, então resta saber de que forma o recurso chegaria aos aplicativos da Meta.
Aliás, a empresa não fez nenhum anúncio oficial da implementação do Voicebox no Instagram, WhatsApp ou Facebook. Por enquanto, tudo leva a crer que Zuckerberg deseja apenas demonstrar os avanços que a empresa está fazendo no campo da IA generativa. Este é o principal foco do momento, junto com o desenvolvimento (de longo prazo) em tecnologias de metaverso.
A Meta não está sozinha na pesquisa e desenvolvimento de IA generativa para voz. O anúncio desta sexta-feira me lembrou do Vall-E, sistema apresentado pela Microsoft em janeiro com a proposta de receber áudios curtos, da própria pessoa falando, para gerar novos arquivos.
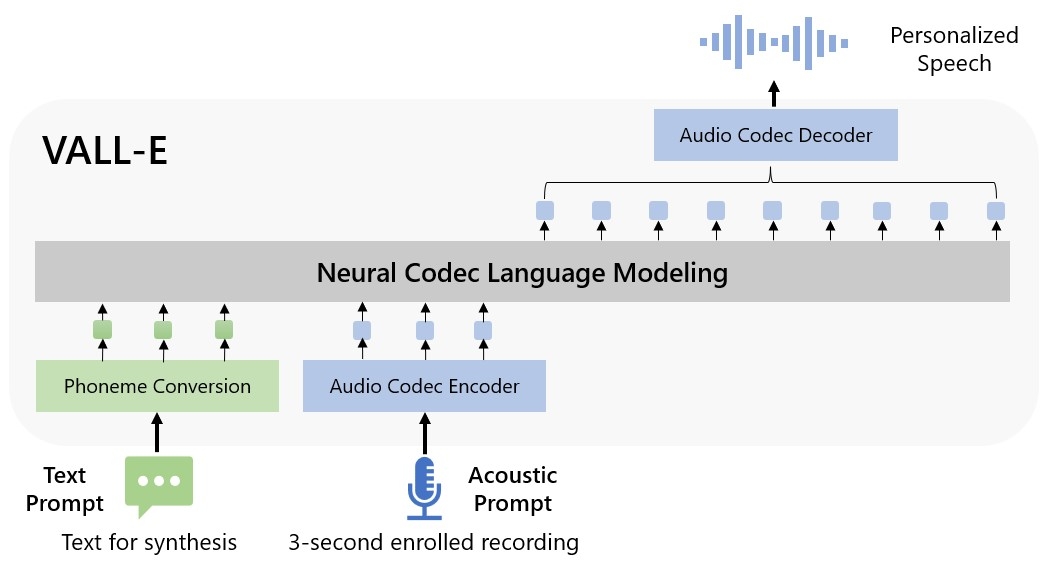
Já a Apple apresentou um recurso batizado de Personal Voice na WWDC 2023, realizada na semana passada. Ele estará no iOS 17. Como parte dos esforços de acessibilidade, usuários poderão ler em voz alta um script de frases. Depois, o sistema do iPhone passará a recriar a voz sintetizada da pessoa. A tecnologia da Apple, porém, requer cerca de 15 minutos de gravação original.
Com informações: Meta, Facebook Research e 9to5 Mac
![Como entender o meta do LoL [League of Legends]?](https://files.tecnoblog.net/wp-content/uploads/2020/07/como-jogar-lol-340x191.jpg)





