Google admite que o Bard vai vasculhar seus dados e posts na web
Política de privacidade agora inclui modelos de inteligência artificial. Plataformas como Twitter e Reddit tentam se proteger do data scraping.

Política de privacidade agora inclui modelos de inteligência artificial. Plataformas como Twitter e Reddit tentam se proteger do data scraping.
A política de privacidade do Google passou por atualizações no começo de julho que servem de chancela para que o Bard e outras tecnologias de inteligência artificial vasculhem a internet em busca de informações. Até mesmo as postagens das pessoas em variadas redes – inclusive minhas e suas, não se engane – poderão ser utilizadas para abastecer os sistemas de IA.
Esta é a primeira vez que o Google coloca num documento qual será a abordagem em torno de fontes de informação para tecnologias de IA. Uma versão anterior do documento estipulava que estes conteúdos poderiam ser lidos e reproduzidos por LLMs. Agora, a terminologia mais ampla – mencionando “modelos de IA” – permite ao buscar treinar outras ferramentas com base nas nossas informações “públicas”.
Em resposta ao portal The Verge, a porta-voz Christa Muldoon disse que a política de privacidade “sempre foi transparente no sentido de que o Google usa informações publicamente disponíveis na web aberta para treinar modelos de linguagem para serviços como o Google Tradutor”. A atualização mais recente, percebida primeiro pelo Gizmodo, seria apenas para esclarecer que serviços mais novos, como o Bard, também estão inclusos. O documento ainda cita as ferramentas de IA do Google Cloud.
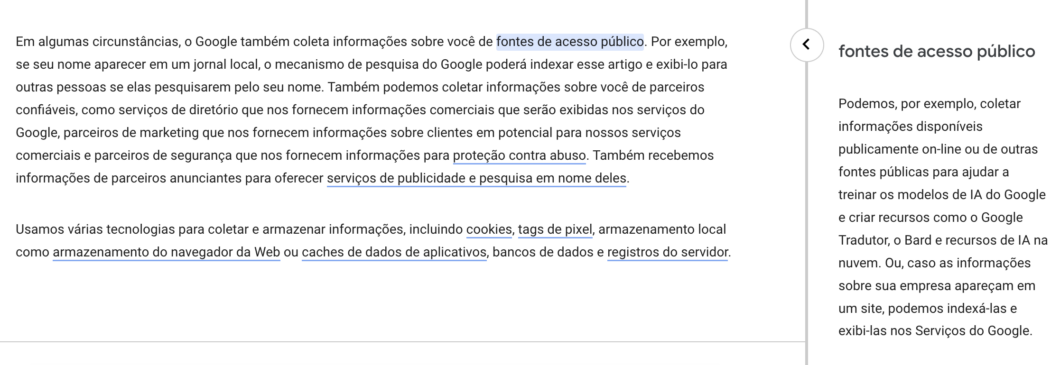
O Verge destaca que a documentação oficial não dá detalhes sobre como o Google e o Bard irão agir diante de material protegido por leis de copyright. Esta é uma das discussões mais quentes em torno da inteligência artificial generativa, que leva em consideração o que foi produzido no passado para recriar frases supostamente próprias.
Diversos sites proíbem a prática de coleta de dados. Tanto é assim que, na semana passada, o Twitter começou a limitar a visualização de tweets por usuários sem perfil na rede social.
Em seguida, o proprietário da plataforma, Elon Musk, determinou uma cota na quantidade de postagens que todos poderiam ver dentro do Twitter. Hoje em dia, me parece que a “taxa limite” não está mais valendo.
Na ocasião, Musk disse que a medida seria para proteger o Twitter de bots e data scraping. Discussão similar está acontecendo nos fóruns do Reddit.

O Bard é tratado publicamente como um “experimento” de inteligência artificial. Ele está à disposição de usuários em quase 200 países, que desejam testar as capacidades da busca do Google em propor respostas para as perguntas feitas pelas pessoas.
O Google costuma dizer que o Brasil é um país prioritário, mas o Bard não está à disposição no mercado doméstico. A empresa não explicou a ausência durante um grande evento realizado em São Paulo no fim de junho. Mistério.
Com informações do The Verge e Gizmodo